1 Introduction & Terminology
1.1 Introduction
1.2 Some terminology
1.3 Hyperdocument contents

Picture 1: Some characterisations and examples of the six media
component categories of hyperdocuments.
![]() Sound is used in hypermedia as an element to create a spatial or
emotional atmosphere, or to control and pace the user like rythmically
tightening bell sound often used in quizzes when the time is running
out. Last but not least sounds are often used as alarming or notifying
effects or cues, earcons. An example of an Audio User-Interface design
may be found in (Mynatt, Edwards).
Sound is used in hypermedia as an element to create a spatial or
emotional atmosphere, or to control and pace the user like rythmically
tightening bell sound often used in quizzes when the time is running
out. Last but not least sounds are often used as alarming or notifying
effects or cues, earcons. An example of an Audio User-Interface design
may be found in (Mynatt, Edwards).
![]() Still images can be hand drawn, scanned, photographed, grabbed from
video or visualised from non-visual sources. They may come from a
photographic source or they can be graphic, computer or man-made.
Important characteristics for the production of images are colour
schemes, absolute size, resolution and filetype, these are the
properties that need to be decided at the earliest - so that resource
requirements (amount of work, computing time and memory requirements)
can be estimated.
Still images can be hand drawn, scanned, photographed, grabbed from
video or visualised from non-visual sources. They may come from a
photographic source or they can be graphic, computer or man-made.
Important characteristics for the production of images are colour
schemes, absolute size, resolution and filetype, these are the
properties that need to be decided at the earliest - so that resource
requirements (amount of work, computing time and memory requirements)
can be estimated.

Picture 2: An example of a computer manipulated photo.
![]() Moving images means literally anything that moves: multivision,
animation, video, morph or model. There are two totally different
approaches to movies on a computer, either every image displayed is
previously produced or images are computed as they are displayed. The
attributes that one needs to decide on are frame rates, frame sizes and
amount of colors. Quite often it makes sense to use animation instead of
videoclips and cut down memory requirements. Animation is very cost
effective and has in many applications even higher information content
than video.
Moving images means literally anything that moves: multivision,
animation, video, morph or model. There are two totally different
approaches to movies on a computer, either every image displayed is
previously produced or images are computed as they are displayed. The
attributes that one needs to decide on are frame rates, frame sizes and
amount of colors. Quite often it makes sense to use animation instead of
videoclips and cut down memory requirements. Animation is very cost
effective and has in many applications even higher information content
than video.

Picture 3: A morph, saved as a QuickTime-clip.
![]() Video just pours information on the viewer who has no control over
the rythm nor the flow of information therein. In manual work external
pacing is considered bad both in view of health and safety as well as
economy and efficiency. Demonstrations introduce interactivity into
documents. The browser can pace herself by pushing control buttons and
okaying dialogues. Demonstration may be defined as application-driven
interaction. Technically demonstration offers a superficial improvement
to video and animation, and is heavily oriented to the story and its
goals. Very often instructional material is organised as demonstrations
because it makes the database cognitively more palatable yet keeping the
author's message clear.
Video just pours information on the viewer who has no control over
the rythm nor the flow of information therein. In manual work external
pacing is considered bad both in view of health and safety as well as
economy and efficiency. Demonstrations introduce interactivity into
documents. The browser can pace herself by pushing control buttons and
okaying dialogues. Demonstration may be defined as application-driven
interaction. Technically demonstration offers a superficial improvement
to video and animation, and is heavily oriented to the story and its
goals. Very often instructional material is organised as demonstrations
because it makes the database cognitively more palatable yet keeping the
author's message clear.
![]() Simulations are the real power of any computer based media. In
simulation we have a model that user can manipulate by changing the
properties and functionalities of its components to make the model
behave differently. Classifications of simulations from pragmatic view
and degree of independence offer an insight into variety of related
genres: games, intelligent environments, training simulations, virtual
realities and artificial life.
Simulations are the real power of any computer based media. In
simulation we have a model that user can manipulate by changing the
properties and functionalities of its components to make the model
behave differently. Classifications of simulations from pragmatic view
and degree of independence offer an insight into variety of related
genres: games, intelligent environments, training simulations, virtual
realities and artificial life.
1.4 Structural definition
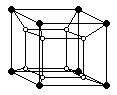
Picture 4: An example of a hyperbolic structure, a hypercube of
4th degree.
![]() We can think of the whole of human knowledge as a recursive whole.
Let us onsider genealogy of sciences: we have mathematics, philosophy,
physics, etc. that are split down to families and groups of problem and
methodology configurations. The hierarchy of disciplines is often highly
interrelated in individual documents. It is not very difficult to
imagine that if we take the 'shells of sciences' away and connect the
inner nodes of problem and method formulations directly, we end up
having the same web - infinite, all-encompassing whole.
We can think of the whole of human knowledge as a recursive whole.
Let us onsider genealogy of sciences: we have mathematics, philosophy,
physics, etc. that are split down to families and groups of problem and
methodology configurations. The hierarchy of disciplines is often highly
interrelated in individual documents. It is not very difficult to
imagine that if we take the 'shells of sciences' away and connect the
inner nodes of problem and method formulations directly, we end up
having the same web - infinite, all-encompassing whole.
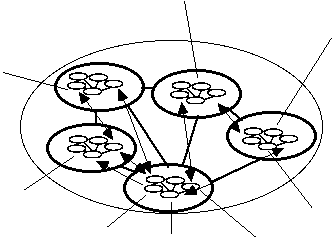
Picture 5: Recursive interpretation - a node within a node within
a node...
![]() In my opinion recursive modelling of hyperstructure relates to
zooming in and out of the structure according to a formulated principle
- e.g changing the level of abstraction. It does not crack the essential
nut: high interconnectivity makes it very hard to start writing a
hyperboard (storyboard for hypermedia) on visually limited and
essentially linear tools. You are entangled in a web of tales and their
connections and you do not really know how to lay them down 'as you
thought' and in collaboration with your team.
In my opinion recursive modelling of hyperstructure relates to
zooming in and out of the structure according to a formulated principle
- e.g changing the level of abstraction. It does not crack the essential
nut: high interconnectivity makes it very hard to start writing a
hyperboard (storyboard for hypermedia) on visually limited and
essentially linear tools. You are entangled in a web of tales and their
connections and you do not really know how to lay them down 'as you
thought' and in collaboration with your team.
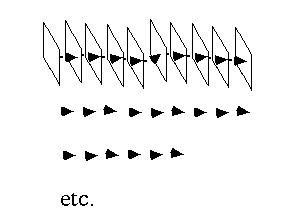
Picture 6: a diagrammatic representation of multiple choises in
Montage en Dix Parts
![]() Interactive piece Montage en Dix Parts: I present you a stack of ten
photographs. You shuffle them and then read them: the sequence of ten
makes up one story. You can reshuffle and read for as long as you like.
With only ten cards, one can come up with plethora of over 3.6 million
sequences. The artistic challenge lies in finding the proper pictures to
carry enough meaning and interest.
Interactive piece Montage en Dix Parts: I present you a stack of ten
photographs. You shuffle them and then read them: the sequence of ten
makes up one story. You can reshuffle and read for as long as you like.
With only ten cards, one can come up with plethora of over 3.6 million
sequences. The artistic challenge lies in finding the proper pictures to
carry enough meaning and interest.
![]() Ted Nelson started the discussion about framing or chunking of
information, how a human being according to her interests and abilities
frames or chunks out parts of hyperdocument - as well as her own sensory
surroundings. (Nelson) Whenever a user
is navigating through this web,
she always has some sort of frame of concentration, which she
understands: I am here, this is a whole, those are parts of that and so
on. In real world we perseive and distinguish objects and their
relations - this is also true of abstractions like thoughts and
hypermedia. These relations fall into two categories: is-a-part-of and
is-a-kind-of. Hierarchies are inherent in former category and often very
well understood by any body. But what about collections and sequencies
of is-a-kind-of entities? I claim that the natural way for us is to
organise these into causalities, narratives and spacial or functional
structures. Hyperdocument can be defined as a collection of is-a-kind-of
objects that represent collections of is-a-part-of objects that are
framed out for the reader. Because links representing both relations
(narration and dialogue) lie in the same visual whole hidden behind the
hot spots, it is very easy to confuse them. It is the task of author to
provide the reader with adequate cues to differentiate them.
Ted Nelson started the discussion about framing or chunking of
information, how a human being according to her interests and abilities
frames or chunks out parts of hyperdocument - as well as her own sensory
surroundings. (Nelson) Whenever a user
is navigating through this web,
she always has some sort of frame of concentration, which she
understands: I am here, this is a whole, those are parts of that and so
on. In real world we perseive and distinguish objects and their
relations - this is also true of abstractions like thoughts and
hypermedia. These relations fall into two categories: is-a-part-of and
is-a-kind-of. Hierarchies are inherent in former category and often very
well understood by any body. But what about collections and sequencies
of is-a-kind-of entities? I claim that the natural way for us is to
organise these into causalities, narratives and spacial or functional
structures. Hyperdocument can be defined as a collection of is-a-kind-of
objects that represent collections of is-a-part-of objects that are
framed out for the reader. Because links representing both relations
(narration and dialogue) lie in the same visual whole hidden behind the
hot spots, it is very easy to confuse them. It is the task of author to
provide the reader with adequate cues to differentiate them.
1.5 Hierarchies, trees and stars
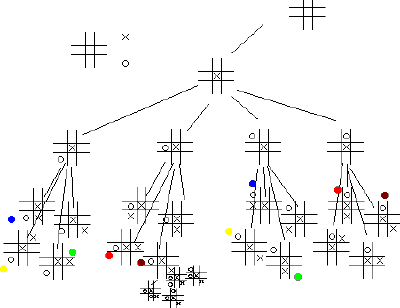
Picture 7: Partially drawn game tree for TIC-TAC-TOE. The
colored dots represent similarities in branches.
![]() A complete game tree is redundant, ie. some branches are equal, some
branches are projections of others etc. When redundant branches are
unified tree- structure is transforms into a graph. Similar structural
difficulties rise if the player is allowed to undo moves.The problem is
that when you take one move back it is still acceptable, but if you are
allowed to retrace a couple of more moves, then the nice hierarchical
organisation falls apart and becomes a graph.
A complete game tree is redundant, ie. some branches are equal, some
branches are projections of others etc. When redundant branches are
unified tree- structure is transforms into a graph. Similar structural
difficulties rise if the player is allowed to undo moves.The problem is
that when you take one move back it is still acceptable, but if you are
allowed to retrace a couple of more moves, then the nice hierarchical
organisation falls apart and becomes a graph.
![]() If you are building a hypermedia document or a computer game you may
want to start by constructing a game tree. However it is important to
realise that you are working with a hyperbolic structure - a hypergraph
that you want to constrain (aesthetically) so that it presents
navigational sequences that unfold over time.
If you are building a hypermedia document or a computer game you may
want to start by constructing a game tree. However it is important to
realise that you are working with a hyperbolic structure - a hypergraph
that you want to constrain (aesthetically) so that it presents
navigational sequences that unfold over time.
![]() Finally we have centered and starlike structures: consider a map of
Helsinki with interactive pop-up explanations of sights and buildings
and a visual dictionary. One could safely call that a star structure
with a nucleus for an index to the whole document. With star structures
one ends up navigating in graphs only crossing the nucleus or index more
often than other parts of the document. One cannot get rid of
hyperbolic graph structures no matter what.
Finally we have centered and starlike structures: consider a map of
Helsinki with interactive pop-up explanations of sights and buildings
and a visual dictionary. One could safely call that a star structure
with a nucleus for an index to the whole document. With star structures
one ends up navigating in graphs only crossing the nucleus or index more
often than other parts of the document. One cannot get rid of
hyperbolic graph structures no matter what.
1.6 Universal access is easy
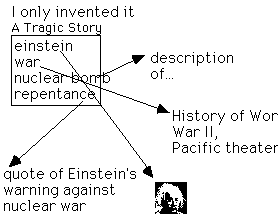
Picture 8: Association through reference by name is the basis of
all
hypermedia.
![]() I want to underline that it is not difficult to implement universal
linking, the real trick of a hyperboarder is to name all components in
is-a-part-of and is-a-kind-of categories so that they relate
meaningfully to the dialogue and narrative.
I want to underline that it is not difficult to implement universal
linking, the real trick of a hyperboarder is to name all components in
is-a-part-of and is-a-kind-of categories so that they relate
meaningfully to the dialogue and narrative.